
AI/ML RAG VS Fine-tuning
When to use which.

I’m sure many of you have heard “fine-tuning” in the context of artificial intelligence at this point. There are probably a lot fewer of you who have heard about RAG (Retrieval-Augmented Generation). I’ll break down both of these concepts, and I’ll provide clear insight on when to use the RAG framework and when to fine-tune your own ML (Machine Learning) model. If you’ve fine-tuned models before, you may come to find out that RAG would have not only saved you ample time and resources but also would have been the right tool for the job to begin with. That’s how I found out.
Fine-tuning
In the era of AI/ML, buzzwords and “buzz” terms are thrown around left and right as though humanity is in a global half-decade-long game of hot potato. Terms are used interchangeably, some words are just used incorrectly, and some terms/words have their meanings changed *ahem* AGI *ahem*. So I will define fine-tuning technically.
Fine-tuning is the process of adapting a pre-trained machine learning model with a smaller, more specific dataset to adapt it for a particular task or use case.
This essentially means: Let’s say you created a video game that has some traction but is nowhere near Steam’s top charts. You decide you want an AI companion that can tell users about the game, the items in the game, and the quests. You would have two options.
Create your own model.
Find a pre-trained model you like, then fine-tune it with data from the game.
Option two saves you an insane amount of time, or a slightly less insane amount of time, and also thousands of dollars for the task.
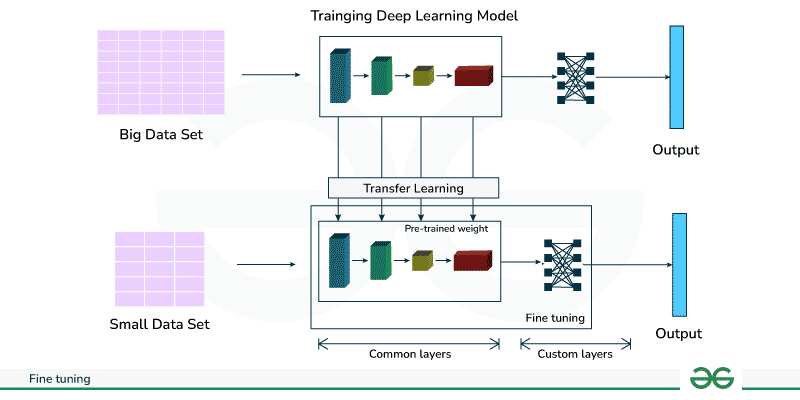
By fine-tuning, you’re essentially “borrowing” the brain of an existing model and then nudging it toward your discipline until it understands the nuances and specifics of your game. You would be starting with a model that already knows the basics of natural language, context, and structure. Now, you can simply show, or “teach”, the lore, the items, the mechanics, and the quirks of your game so it can answer questions like “What can I do with these potions?” Once the model is fine-tuned, to add more information or context continuously, you would have to continue fine-tuning it.
Well, what if you have a small flower boutique in a secluded part of Hamilton, New Jersey, and you want to create an AI chatbot that talks to users on your website, and can answer questions like “Do you deliver to Princeton?”, or “Do you have special holiday hours?” Then the RAG framework sounds like a better tool for the job…
RAG - Retrieval-Augmented Generation
RAG is the process of enhancing large language models by passing in external knowledge to improve accuracy and relevancy for a particular topic.
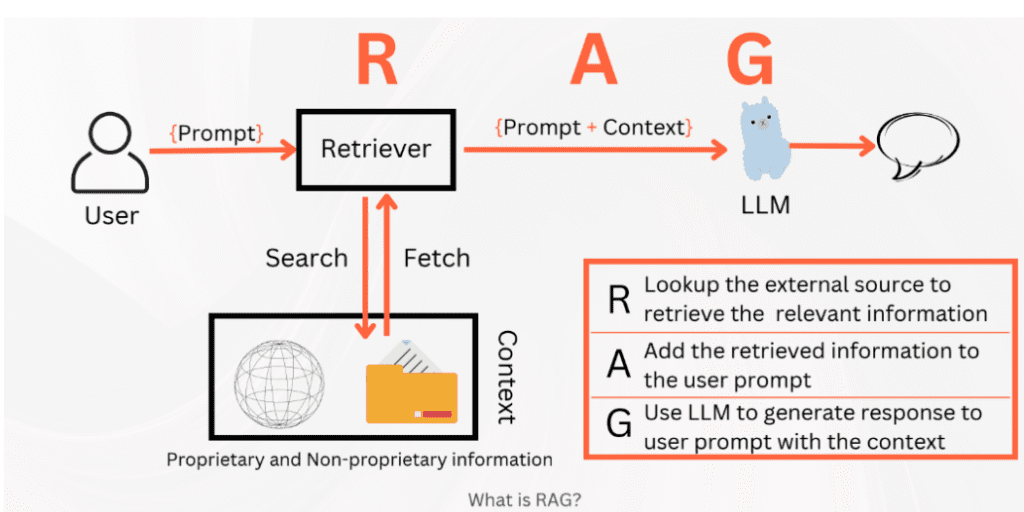
In the diagram above, we can follow along with the process. The user first asks: “Do you deliver to Princeton?” This question hits the retriever and searches for the external knowledge (can be a single text file) and grabs the external knowledge. The external knowledge is then attached to the prompt as extra context before finally being passed into the LLM (Large Language Model), and a response is then generated using the prompt + context.
In this case, we can imagine the external knowledge used was the shop owner’s FAQ, which is also hosted on the website. This is an easy way to access the information if both the chatbot and the FAQ page are tied into the same project. Additionally, whenever the owner updates the FAQ, the external knowledge is updated as well, allowing for dynamic changes in the bot’s response. This would not have been the case had fine-tuning been used.
When to use RAG and when to Fine-tune?
In many cases, RAG will often be the default choice. There are even cases in the game example where RAG can work for you instead of against you, allowing you to save time and money as you develop other parts of the game. Another benefit of RAG is that when switching language models, you don’t have to redo the process, as you would with fine-tuning; you simply switch which model the external knowledge is passed to.
Fine-tuning, however, can alter the way the model responds to the user. RAG does not do this. This means if you are fine-tuning a model, it will almost always have the potential to be more unique and concise than if you were to use RAG, at the cost of locking you into an LLM choice, which just requires a decent amount of research before making your decision.
Well, that doesn’t sound like a very definitive answer…
Okay, here it is:
Use RAG if you are working with knowledge that changes often, like product inventories, handbooks, or anything dynamic and would be almost impossible to restrain. RAG is flexible, far easier to implement, and allows you to focus on curating data rather than trying to play with weights.
Use fine-tuning if you need your AI bot to “sound” a certain way, or carry a consistent personality. If your task is very narrow and requires precision and style, then you should go with fine-tuning.
Ultimately, RAG is like renting a library card with instant access to the latest shelves, while fine-tuning is publishing your own textbook that never changes once it’s printed.
I’ll write more in-depth about both of these soon, but you should now be able to make a more informed decision on how you should tackle your AI/ML tasks. Thanks for reading!